一、MySQL 配置
1 | [mysqld] |
二、查看配置的命令
1 | -- 查看事件是否开启。 |
PRESERVE 表示此次执行完不删除该事件,等到下次继续执行。
三、附
1. 关于分布式主键的几个问题
在 MySQL 的分布式架构中,为什么不能使用自增主键?
- 如果基于主键范围分片,压力可能集中在某个分片,采用其它业务字段 hash 分片,可以缓解压力
- 如果使用 auto_increment 和 replace into 自增 ID,每当插入数据时,都会占用自增锁和插入锁
- 分布式系统中,每个节点都会有自己的自增 ID,合并数据时,会出现 ID 冲突
UUID 可以做主键?存在哪些问题?
- 由于其生成随机、无序,所以会发生索引断裂、磁盘碎片。
- uuid 的问题可以通过有序 uuid 来解决,MySQL 8.0 提供
uuid_to_bin函数来互换uuid的时间低位和高位,将无序的 uuid 转为有序的 uuid,同时保证了唯一性和有序性,也能解决索引性能下降的问题。
雪花算法生成的 id 有什么缺点?
雪花算法的原理:把当前时间戳转为 unix_time 形式,再将 unix_time 形式的时间戳转为 二进制 数字,这串二进制数据长度为 41 bit。在前面补 0 当作符号位。机器编码的二进制补到 10 bit 机器编号位置,序列号的二进制补到 12 bit 序列号位置,最后把这一长串转为 10 进制数字,这串数字就是该算法生成的 id。
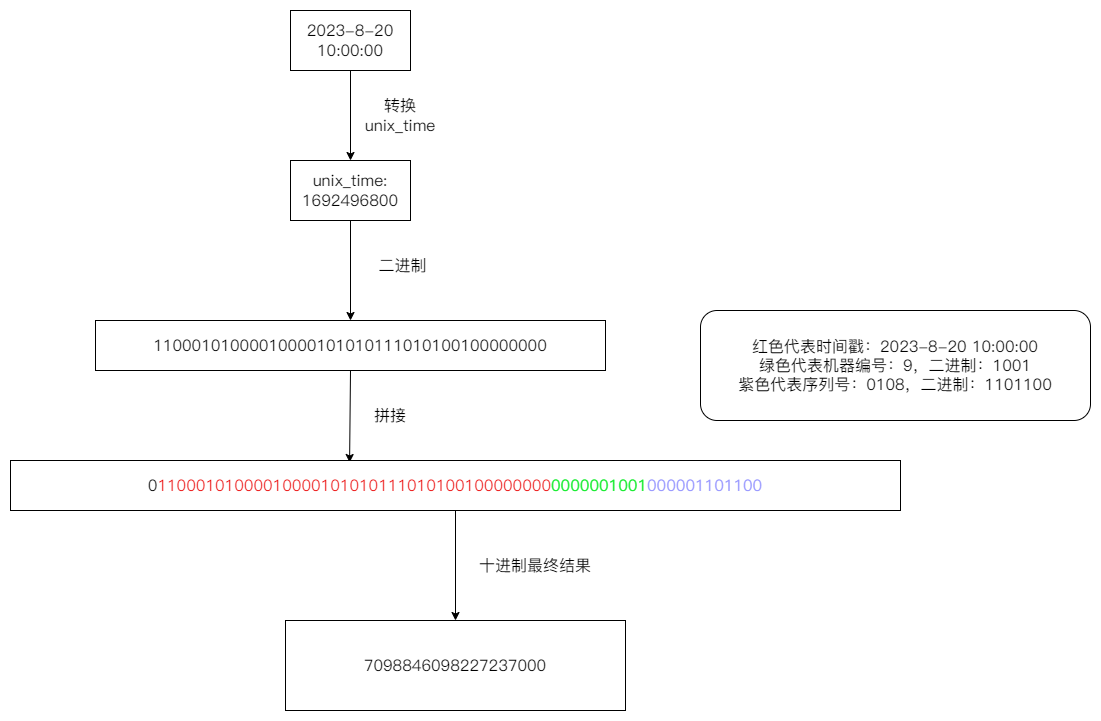
雪花算法基于时间戳的自增完成的,可以实现分布式的部署;所以缺点也是显而易见:高度依赖服务器的时间。如果时间发生了回拨,就会出现时间重复,对应生成的 id 可能会重复。
另外 41 bit 存储的时间跨度是 69 年。而 unix_time 从 1970 年算起,到现在已经过去了 53 年,所以现在生成的可以使用 16 年,会出现 41 bit 不够用的情况。可以使用当前时间减去系统的上线时间,这样可以使用 69 年。
Unix 时间戳是从 1970 年 1 月 1 日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。
四、MySQL 调优
优化是相对的。
引擎分类
InnoDB
InnoDB 包含四种索引类型
| 类型 | 说明 |
|---|---|
| 主键索引 | innoDB 默认为聚簇索引,该列的值不能为 null; |
| 单值索引 | 普通索引):一个索引只包含单个列; |
| 唯一索引 | 该列的值允许为 null; |
| 复合索引 | 多列的值; |
MyISAM
全文索引
MySQL 的最左包含原则是条件中含有最左的字段,但并不限制该字段所在的位置顺序。
优化口诀
阿里巴巴手册中说:SQL优化标准是到 ref,最差是 range,达到 const 最好。
索引失效:
全值匹配最喜欢,最左前缀规矩严。
带头大哥不能死,中间兄弟不能断。
索引列上少计算,范围之后全完蛋。
LIKE百分最右边,覆盖索引*全不见。
不等空值还有OR,你建索引也失效。
VAR引号要出现,SQL高级也不难。
建立索引口诀:
主键索引自动建,频繁查询索引现;
查询关联其他表,外键索引也要看;
频繁更新引不建,where条件用到算;
单键/组合选择难,高并发下组合建;
若要速度有体现,排序字段索引建;
统计、分组你咋看?索引索引建建建。
一般守则
-
尽量不在数据库做复杂运算;
-
单库不超过 300~400 张表,单表不超过 500w 数据,表字段控制在 20~50 个;
- 顺序读1G文件需N秒,单行不超过 200 Byte
- 单表不超过50个纯INT字段
- 单表不超过20个CHAR(10)字段
-
在一些场景中,不必严格遵循三范式,可以适当时牺牲范式,加入冗余;
-
防止 3B:Big SQL、Big Transaction、Big Batch;
-
统一字符集为UTF-8
-
统一命名规范
- 库表等名称统一用小写,注意避免用保留字命名。
- 索引命名默认为“idx_字段名”
- 库名用缩写,尽量在2~7个字母
字段
1. 用好数值类型
TINYINT(1Byte)、SMALLINT(2B)、MEDIUMINT(3B)、INT(4B)、BIGINT(8B)、FLOAT(4B)、DOUBLE(8)、DECIMAL(M,D)
数字型VS字符串型索引:
- 更高效
- 查询更快
- 占用空间更小
用无符号INT存储IP,而非CHAR(15),使用数据库的函数去查看INT UNSIGNED、INET_ATON()、INET_NTOA()
2. 少用并拆分TEXT/BLOB
TEXT 类型处理性能远低于 VARCHAR,会强制生成硬盘临时表,浪费更多空间:VARCHAR(65535) ==> 64K (注意UTF-8);
尽量不用TEXT/BLOB数据类型,若必须使用则拆分到单独的表
3. 不在数据库里存图片
索引
1. 合理添加索引
- 改善查询
- 减慢更新
- 索引不是越多越好,需要综合评估数据密度和数据分布;最好不超过字段数20%,结合核心SQL优先考虑覆盖索引
不要给“性别”列创建索引
2. 不在索引列做运算
不在索引列进行数学运算或函数运算,否则会导致无法使用索引以及全表扫描。
3. 自增列或全局ID做INNODB主键
- 对主键建立聚簇索引
- 二级索引存储主键值
- 主键不应更新修改
- 按自增顺序插入值
- 忌用字符串做主键
- 聚簇索引分裂
- 推荐用独立于业务的 AUTO_INCREMENT 列或全局 ID 生成器做代理主键
- 若不指定主键,InnoDB会用唯一且非空值索引代替
4. 尽量不用外键
尽量不使用外键,由程序来保证约束,实际中确实很少使用。虽然外键可节省开发量,但是有额外开销:逐行操作,可‘到达’其它表,意味着锁;在高并发场景容易死锁。
SQL
-
SQL语句尽可能简单
-
保持事务连接小
-
尽可能避免使用SP/TRIG/FUNC
- 尽可能少用存储过程、触发器;减用使用MySQL函数对结果进行处理,由客户端程序负责。
-
尽量不用SELECT *,只取需要的数据列
-
改写OR为IN()
同一字段,将OR改写为IN()。 OR效率:O(n),IN 效率:O(Log n)
当n很大时,OR会慢很多。注意控制IN的个数,建议n小于200。
1
2select * from opp WHERE phone='12347856' or phone='42242233';
select * from opp WHERE phone in ('12347856' , '42242233'); -
改写OR为UNION
不同字段,将or改为union
- 减少对不同字段进行 “or” 查询
- Merge index往往很弱智,如果有足够信心:
set globaloptimizer_switch='index_merge=off';
1
2
3
4
5
6-- 原写法
select * from opp WHERE phone='010-88886666' or cellPhone='13800138000';
-- 优化写法
Select * from opp WHERE phone='010-88886666'
union
Select * from opp WHERE cellPhone='13800138000'; -
LIMIT高效分页
LIMIT 的偏移量越大则查询越慢。
1
2
3
4
5
6-- 分页方式一
Select * from table WHERE id>=23423 limit 11;
-- 分页方式二
Select * from table WHERE id >= ( select id from table limit 10000,1 ) limit 10;
-- 分页方式三
SELECT * FROM table INNER JOIN (SELECT id FROM table LIMIT 10000,10) USING (id) ; -
用UNION ALL而非UNION
若无需对结果去重,则用 UNION ALL,UNION 有去重开销。
-
Load Data导数据
批量数据导入:
- 成批装载比单行装载更快,不需要每次刷新缓存
- 无索引时装载比索引装载更快
- Insert values ,values,values 减少索引刷新
- Load data 比 insert 快约20倍
- 尽量不用
INSERT INTO... SELECT,可能会出现延迟、同步出错
-
Know Every SQL
1
2
3
4
5
6
7EXPLAIN
SHOW PROFILE
Show Slow Log
Show Processlist
SHOW QUERY_RESPONSE_TIME(Percona)
MySQLdumpslow
MySQLsla
附
常用 SQL
MySQL 中有一个辅助表可以用来使用 mysql.help_topic,该表有 159 个自增 help_topic_id,该表可以帮助处理行转列、查询连续的信息。
1 | -- 重置表 ID 从 1 开始自增; id_key 为自增 id |