BPMN 工作流的名词解释:https://www.flowable.com/open-source/docs/bpmn/ch02-GettingStarted。可以在线绘制流程图并下载的网站:
Activiti、Flowable、Camunda
有关这三个工作流框架的渊源,网上有很多的资料可以参考。主要因开发者的理念、意见不合而先后建立,但都基于同一个祖先 JBPM,想要了解这段故事可以自行查找资料。这几个工作流都使用 BPMN 2.0 定义的一些符号来描述流程信息的,但其本质依然是 xml 文件。
BPMN 2.0 是用于业务流程建模的图形化方法,它定义了一组符号和规则,用于描述整个业务流程的各部分内容,它的目的就是提供一种统一的、易于理解的格式来表示业务流程。
目前,这几个工作流框架的最新版本基本都不提供内置的页面绘制工具了(流程设计器),需要额外下载官方提供的工具(Modeler)或者注册登录官方平台免费绘制下载使用。
工作流基础知识
BPMN (Business Process Model and Notation)
BPMN是一种业务流程建模语言,用于描述和定义业务流程的控制流、数据流和资源分配。它提供了一套标准化的符号和规则来描述业务流程,方便业务分析师和开发人员理解和实施业务流程。
一般我们做的业务流程定义都是基于 BPMN,比如 审批工作流。所以查看官方文档时基本只需要看 bpmn 部分,其它的用到再看即可。本文重点也是这部分。
核心概念
流程(Process):一个流程是指一系列的活动和事件,按照特定的顺序执行,以实现特定的业务目标。
活动(Activity):一个活动是指流程中的一项任务或操作,例如填写表格、审批等。
事件(Event):一个事件是指流程中发生的某件事情,例如接收到请求、完成任务等。
网关(Gateway):一个网关是指流程中用来控制流程流向的元素,例如分支、合并等。
CMMN (Case Management Model and Notation)
CMMN 是一种案例管理建模语言,用于描述和定义非结构化或半结构化的业务过程。它提供了一套标准化的符号和规则来描述案例管理流程,方便业务分析师和开发人员理解和实施案例管理。
案例管理是一种标准,它允许对可能以不可预测的顺序执行的不同类型的活动进行建模。在早期,我们通常试图通过拥有极其复杂的 BPMN 图来解决案例管理和 BPM 的问题,其中包含所有可能正确的事情和所有可能出错的事情。但实际上,这不是 BPMN 的工作:BPMN 的工作是有一条从头到尾的路径,这条路径非常清晰,能够被理解,并且每次都以相同的方式工作。
案例管理使我们能够避免每次都以相同的方式工作。例如,可以将流程嵌入到案例中,但总的来说,这是一个非常有趣的新领域,它已经存在了一段时间,但采用速度相当快,现在案例管理也正在实现自动化。
核心概念
案例(Case):一个案例是指一个特定的业务场景或问题,例如客户投诉、保险索赔等。
阶段(Stage):一个阶段是指案例管理流程中的一个阶段,例如接收、处理、关闭等。
任务(Task):一个任务是指案例管理流程中的一个具体任务,例如填写表格、审批等。
决策(Decision):一个决策是指案例管理流程中的一个决策点,例如是否批准、是否拒绝等。
DMN (Decision Model and Notation)
DMN 是一种决策建模语言,用于描述和定义决策逻辑和规则。它提供了一套标准化的符号和规则来描述决策流程,方便业务分析师和开发人员理解和实施决策。
它结合了决策表等的旧思想,具有许多高级和新的工具和思想,例如关系表、可重用的业务知识模块和知识源文档等。这些可以用作可堆肥应用程序中的服务组件的决策。我们看到的是,DMN 不仅连接到 BPMN 中的规则和决策任务,而且还取代了许多组织中专有的非标准(标准很重要)业务规则管理系统。
核心概念
决策(Decision):一个决策是指一个特定的决策点,例如是否批准、是否拒绝等。
决策表(Decision Table):一个决策表是指一个表格,用于描述决策逻辑和规则。
输入数据(Input Data):输入数据是指决策流程中使用的数据,例如客户信息、订单信息等。
输出数据(Output Data):输出数据是指决策流程的结果,例如批准或拒绝等。
BPMN 中的一些概念
流程、任务
流程定义和部署
使用 bpmn 2.0 定义的符号绘制流程节点并按需添加审批人、网关、监听器等(或者直接撸 xml 文件),建立一个完整的审批流程,定义了流程如何流转以及各节点的任务,然后将其信息存入到相对应的表中。工作流引擎会默认生成一个流程图,当然,我们也可以自己上传对应的图片,后续通过工作流提供的 API 获取。
在启动流程时可以根据流程 id 发起,也可以根据流程 key 发起。
流程定义版本号:
- 每次部署相同 key 的流程定义时,Flowable 会自动为该 key 生成递增的版本号(例如,第一次部署版本为 1,修改后重新部署版本为 2,以此类推)。
- 同一 key 的多个版本会共存,但启动流程时流程引擎默认会使用最新 version 的启动实例。
流程实例
启动以此流程生成一个实例。每个流程实例是一个流程定义的一次执行。
任务
任务是工作流框架中的最小执行单位,对应 流程定义 中每个节点用户需要处理的操作;(例如每个审批节点就对应一个任务)。
流程分类
部署流程时可以通过流程引擎的 API 添加分类信息,只不过分类信息需要我们自己维护。、
网关
排他网关(Exclusive Gateway)
定义: 排他网关根据条件表达式来决定激活哪一条流程路径。它会评估离开网关的每个流的条件,如果条件为真,则激活该流。与包含网关不同,排他网关只会激活一个流。
行为: 当流程到达排他网关时,网关会根据条件表达式来决定哪一条流程路径应该被激活。它只会激活一个离开它的流。
使用场景: 需要根据条件选择执行多个任务或活动,但只能选择一个任务执行的场景。
并行网关(Parallel Gateway)
定义: 并行网关允许流程在同一时刻沿着多条路径同时继续执行。它不评估条件,即所有到达并行网关的流都会被激活,并且所有离开网关的流都会被激活。
行为: 当流程到达并行网关时,网关会激活所有离开它的流,允许流程同时沿着这些路径继续执行。并行网关通常用于将单一流程分割成多个并行执行的分支,也可以合并多个并行执行的分支。
使用场景: 需要同时执行多个任务或活动的场景。
包含网关(Inclusive Gateway)
定义: 包含网关根据条件表达式来决定激活哪些流程路径。它会评估离开网关的每个流的条件,如果条件为真,则激活该流。与并行网关不同,包含网关可能只激活一个或多个流。
行为: 当流程到达包含网关时,网关会根据条件表达式来决定哪些流程路径应该被激活。它可以激活一个或多个离开它的流,但不保证所有离开它的流都会被激活。
使用场景: 需要根据条件选择执行多个任务或活动,但不需要所有任务都必须被执行的场景。
事件网关(Event Gateway)
定义: 事件网关是基于事件的网关,它等待特定的事件发生后才会激活流程的下一步。事件网关不需要流程流到达它,而是等待特定事件的触发。
行为: 事件网关在等待特定事件发生时处于等待状态。一旦事件发生,它会激活流程的下一步。事件网关通常用于处理外部事件或异步事件。
使用场景: 需要等待外部事件或异步事件触发后才继续执行流程的场景。
除了上面的几种网关分类之外,还有其它的网关,例如:信号网关、事件基于网关、并行网关的合并等。
其它 编码/业务 概念
会签:一个节点有多个审批人,需要所有审批人都同意或者半数以上的人同意(这个比例在流程绘制时可以控制)才能进入下一个节点;
或签/非会签:一个节点有多个审批人,任一审批人同意即可进入下一节点;
加签:在节点中添加审批人;
减签:在节点中去除审批人;
抄送和退回(驳回)比较简单,不再解释。
在线表单和业务表单
在现流行的 ruoyi flowable 的免费衍生框架中,大部分都是使用的在线表单,一般分为两种:
- 路由表单:自己编写的前端页面:vue 或者 html 使用 json 把整个页面存储在数据库中,使用流程变量存储相关信息,使用时需要按照模板编写,比较繁琐,和正常写前端页面相比不完美的地方很多;
- 在线表单:使用一些绘制工具(vForm 等),在页面上使用拖拉拽方式编辑布局,使用表达式或者变量自行设计的表单;
无一例外,都在数据库中存储了表单的结构,不说读取速度如何,单纯就复杂业务来讲,难以满足,只有非常简单的情况下才去使用(简单的审批自己实现就好,也不需要引入流程框架)。
业务实现中一般使用外置表单/业务表单,该表单内容对应数据库中的一张/多张表,和平常业务页面相同。但是需要在业务表中增加两个与工作流相关的字段:流程实例id (processInstanceId) 和审批状态,这样我们就可以据此追溯流程的内容和结果,并且借助 flowable 的监听器去同步状态。如果需要双向绑定,可以在启动流程时,使用三个参数的重载版本,将记录 id 放进去,以供后续查询使用。
Flowable
Flowable 7.x 是目前最新的版本,专注于 Spring Boot 3、Spring 6 和 Java 17 的升级适配。从这个版本开始,删除了内置的 web ui 流程设计器,官方推荐注册一个 flowable 云平台的账号免费在上面进行流程绘制。
引入依赖
1 | <dependency> |
配置文件:
1 | spring: |
如果是多数据源,且内部对数据源的重写程度较大(比如自定义了 sqlSessionFactory),那么 flowable 可能不会读取配置,程序启动时还是使用内置的 h2 数据库,如果有无法建表的错误,大概率是此原因。
配置文件:
1 | spring: |
读取 flowable 的配置:
1 |
|
设置数据源:
1 |
|
但是上面的解决办法可能会引入新的问题:数据源切换事务可能会出问题,不过由于目前没有用到多数据源(采用的框架支持),所以没有深入。
表结构说明
flowable 启动时如果数据库没有相关的表结构会自动创建,一共有 70 张表,根据表前缀分类大致如下:
ACT_RE_:RE 代表 repository(存储)。这些表包含静态信息,如流程定义和流程的资源(图片、规则等)。由 RepositoryService 接口操作。
ACT_RU_:RU 代表 runtime。这些表存储运行时信息,如流程实例、用户任务、变量、作业等。Flowable 只在流程实例运行中保存运行时数据,并在流程实例结束时删除记录,以保证运行时表小且快。由 RuntimeService 接口操作。
ACT_HI_:HI 代表 history。这些表存储历史数据,如已完成的流程实例、变量、任务等。由 HistoryService 接口操作。
ACT_ID_:ID 表示 identity(组织机构)。这些表包含标识的信息,如用户、用户组等。由 IdentityService 接口操作。
ACT_GE_:通用数据表,用于存储各种情况下都可能需要的数据。
还有其它的表,但是使用的频率应该不高?
核心表:
ACT_GE_BYTEARRAY:xml 文件元数据;
ACT_RE_DEPLOYMENT:绘制的 xml 文件信息保存在这里面,并且带着自定义的名称和分类等基础信息;
ACT_RE_PROCDEF:流程定义表,一次部署可以部署多个流程,一个流程对应一条记录,key 默认是 xml 的 id;
ACT_RU_ACTINST:流程实例表,对应申请用户发起的审批申请;
ACT_RU_TASK:用户任务表,工作流执行的最小单位,该表存储每个流程实例当前运行到的那个节点信息,每个任务完成后自动删除(常用于查询人员或部门的待办任务);
ACT_RU_EXECUTION:执行分支表,记录运行中流程运行的各个分支节点信息,流程结束后删除;
ACT_HI_PROCINST:历史流程实例表,存储流程实例历史数据(包含正在运行的流程实例)。每启动一个流程实例,ACT_HI_PROCINST 中就会维护一条记录;
详细说明参考:https://documentation.flowable.com/latest/develop/dbs/overview
表达式
接入自己系统的组织架构和人员
已存在的系统需要接入 flowable,我们基本不会使用内置的认证,而是需要接入自己系统的组织和人员。实现方式多种多样,一般会在流程绘制阶段在 userTask 中直接设置,因为审批人多数情况下不会变动。此时通过后端返回已有的用户以及组织列表(就像系统管理的用户管理),前端做一个弹窗进行展示以及选择,然后传给后端,无论是用户的 id 还是用户名,只要能据此查找到用户就行,后面就交给后端实现。
在绘制的 xml 流程图阶段,userTask 标签中有一个 assignee 的属性,把能代表用户的标志传给后端,并且 flowable 会存储在自己的表中。主要是在前端页面设计接入,传递给后端即可。candidateUsers 是候选用户,candidateGroups 候选组,满足多种不同的需求。
1 | <!-- 截取部分说明,flowable:assignee 的值为 3,这是数据库用户的 id --> |
监听器
ExecutionListener 执行监听器
执行监听器有三种触发类型:start 启动、end 结束、take 连线。执行监听器可以处理在流程过程中发生的特定事件,需要实现 ExecutionListener 接口。
流程实例的启动和结束
流程执行转移
活动的启动和结束
网关的启动和结束
中间事件的启动和结束
启动事件的结束,和结束事件的启动
TaskListener 任务监听器
任务监听器有六种触发类型:create 创建、assignment 委派、complete 完成、delete 删除、update 更新、timeout 超时事件。任务监听器主要处理用户的任务节点,实现 TaskListener 接口类。
流程变量
流程变量也是工作流提供的核心功能之一。主要分为两大类,全局变量(Process Variables)、局部变量(Local Variables)。
全局变量与流程实例绑定,生命周期与流程实例一致,整个流程中都可以访问。
局部变量与某个执行节点或任务绑定,生命周期仅限于该节点或任务,其他节点无法访问。
变量都是 map 结构,所以如果定义了同名的变量,后面的会覆盖前面的。
一个流程实例可以拥有任意数量的变量,每个变量都存储在 ACT_RU_VARIABLE 数据库表的一行中。可以在启动或创建流程实例时添加(startProcessInstanceXXX()),也可以在流程执行期间添加(RuntimeService)。
变量经常在Java 委托、表达式、执行或任务监听器、脚本等中使用。由于历史原因(和向后兼容性),在执行获取流程变量的 API(getvariables()) 调用时,后台会从数据库中获取所有变量。这意味着如果你有 10 个变量,但只通过 getVariable(“myVariable”) 获取一个,后台会获取并缓存其他 9 个。这不一定是坏事,因为后续调用将不会再次访问数据库。当使用大量变量或者只是想要严格控制数据库查询和流量时,这种方式并不合适。为了对此进行更严格的控制,flowable 引入了额外的重载方法,通过添加具有可选参数的新方法,该参数告诉引擎是否获取和缓存所有变量。
代码示例
flowable starter 的操作 bean
使用 Flowable 的 starter,这些 bean 可以通过 IOC 注入直接使用,也可以使用 ProcessEngine#getXXX 的方式获取:
1 | // 第一种,通过 processEngine 获取 |
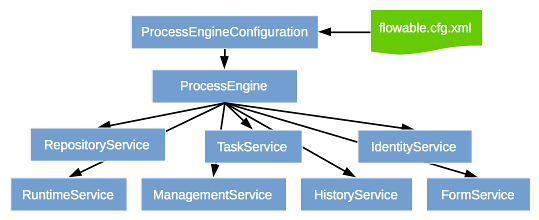
RepositoryService 主要处理静态数据,RuntimeService 则正好相反。