BPMN 工作流的名词解释:https://www.flowable.com/open-source/docs/bpmn。可以在线绘制流程图并下载的网站:
Activiti、Flowable、Camunda
有关这三个工作流框架的渊源,网上有很多的资料可以参考。主要因开发者的意见不合而先后建立,但都基于同一个祖先 JBPM,想要了解这段故事可以自行查找资料。这几个工作流都是使用 xml 文件来描述流程信息的。
BPMN 2.0 是用于业务流程建模的图形化方法,它定义了一组符号和规则,用于描述整个业务流程的各部分内容,它的目的就是提供一种统一的、易于理解的格式来表示业务流程。
截至本文发文,这几个工作流框架的最新版本基本都不提供内置的页面绘制工具了(流程设计器),需要额外下载官方提供的工具(Modeler)或者注册登录官方平台免费绘制下载使用。也有一些网站提供了流程绘制和下载,例如 BPMN提供的网站 。三款产品目前都在努力进行商业化,积极为云环境做准备。
基础知识
BPMN (Business Process Model and Notation)
BPMN是一种业务流程建模语言,用于描述和定义业务流程的控制流、数据流和资源分配。它提供了一套标准化的符号和规则来描述业务流程,方便业务分析师和开发人员理解和实施业务流程。
一般我们做的业务流程定义都是基于 BPMN,例如 OA 工作流、审批流等。
核心概念
流程(Process):一个流程是指一系列的活动和事件,按照特定的顺序执行,以实现特定的业务目标。
活动(Activity):一个活动是指流程中的一项任务或操作,例如填写表格、审批等。
事件(Event):一个事件是指流程中发生的某件事情,例如接收到请求、完成任务等。
网关(Gateway):一个网关是指流程中用来控制流程流向的元素,例如分支、合并等。
CMMN (Case Management Model and Notation)
CMMN 是一种案例管理建模语言,用于描述和定义非结构化或半结构化的业务过程。它提供了一套标准化的符号和规则来描述案例管理流程,方便业务分析师和开发人员理解和实施案例管理。
案例管理是一种标准,它允许对可能以不可预测的顺序执行的不同类型的活动进行建模。在早期,我们通常试图通过拥有极其复杂的 BPMN 图来解决案例管理和 BPM 的问题,其中包含所有可能正确的事情和所有可能出错的事情。但实际上,这不是 BPMN 的工作:BPMN 的工作是有一条从头到尾的路径,这条路径非常清晰,能够被理解,并且每次都以相同的方式工作。
案例管理使我们能够避免每次都以相同的方式工作。例如,可以将流程嵌入到案例中,但总的来说,这是一个非常有趣的新领域,它已经存在了一段时间,但采用速度相当快,现在案例管理也正在实现自动化。
核心概念
案例(Case):一个案例是指一个特定的业务场景或问题,例如客户投诉、保险索赔等。
阶段(Stage):一个阶段是指案例管理流程中的一个阶段,例如接收、处理、关闭等。
任务(Task):一个任务是指案例管理流程中的一个具体任务,例如填写表格、审批等。
决策(Decision):一个决策是指案例管理流程中的一个决策点,例如是否批准、是否拒绝等。
DMN (Decision Model and Notation)
DMN 是一种决策建模语言,用于描述和定义决策逻辑和规则。它提供了一套标准化的符号和规则来描述决策流程,方便业务分析师和开发人员理解和实施决策。
它结合了决策表等的旧思想,具有许多高级和新的工具和思想,例如关系表、可重用的业务知识模块和知识源文档等。这些可以用作可堆肥应用程序中的服务组件的决策。我们看到的是,DMN 不仅连接到 BPMN 中的规则和决策任务,而且还取代了许多组织中专有的非标准(标准很重要)业务规则管理系统。
核心概念
决策(Decision):一个决策是指一个特定的决策点,例如是否批准、是否拒绝等。
决策表(Decision Table):一个决策表是指一个表格,用于描述决策逻辑和规则。
输入数据(Input Data):输入数据是指决策流程中使用的数据,例如客户信息、订单信息等。
输出数据(Output Data):输出数据是指决策流程的结果,例如批准或拒绝等。
网关
排他网关(Exclusive Gateway)
定义: 排他网关根据条件表达式来决定激活哪一条流程路径。它会评估离开网关的每个流的条件,如果条件为真,则激活该流。与包含网关不同,排他网关只会激活一个流。
行为: 当流程到达排他网关时,网关会根据条件表达式来决定哪一条流程路径应该被激活。它只会激活一个离开它的流。
使用场景: 需要根据条件选择执行多个任务或活动,但只能选择一个任务执行的场景。
并行网关(Parallel Gateway)
定义: 并行网关允许流程在同一时刻沿着多条路径同时继续执行。它不评估条件,即所有到达并行网关的流都会被激活,并且所有离开网关的流都会被激活。
行为: 当流程到达并行网关时,网关会激活所有离开它的流,允许流程同时沿着这些路径继续执行。并行网关通常用于将单一流程分割成多个并行执行的分支,也可以合并多个并行执行的分支。
使用场景: 需要同时执行多个任务或活动的场景。
包含网关(Inclusive Gateway)
定义: 包含网关根据条件表达式来决定激活哪些流程路径。它会评估离开网关的每个流的条件,如果条件为真,则激活该流。与并行网关不同,包含网关可能只激活一个或多个流。
行为: 当流程到达包含网关时,网关会根据条件表达式来决定哪些流程路径应该被激活。它可以激活一个或多个离开它的流,但不保证所有离开它的流都会被激活。
使用场景: 需要根据条件选择执行多个任务或活动,但不需要所有任务都必须被执行的场景。
事件网关(Event Gateway)
定义: 事件网关是基于事件的网关,它等待特定的事件发生后才会激活流程的下一步。事件网关不需要流程流到达它,而是等待特定事件的触发。
行为: 事件网关在等待特定事件发生时处于等待状态。一旦事件发生,它会激活流程的下一步。事件网关通常用于处理外部事件或异步事件。
使用场景: 需要等待外部事件或异步事件触发后才继续执行流程的场景。
除了上面的几种网关分类之外,还有其它的网关,例如:信号网关、事件基于网关、并行网关的合并等。
其它 流程/编码/业务 概念
流程定义:使用 bpmn 2.0 定义的符号绘制流程节点并按需添加审批人、网关、监听器等,这是我们定义的一个完整的审批流程,定义了流程如何流转以及各节点的任务;
流程部署:把上面使用 流程定义语言 绘制的 xml 文件下载并存入到 flowable 相关的数据库表中,以供发起流程审批使用;(模板文件,如果部署了多次,每次新部署的模板记录数据库中的 version + 1,旧模板保存)
流程实例:使用上一步中部署的“模板”发起一个任务,申请人填写相关信息进入审批中;
任务:工作流框架中的最小执行单位,对应 流程定义 中每个节点用户需要处理的操作;((例如每个审批节点就对应一个任务)
会签:一个节点有多个审批人,需要所有审批人都同意或者半数以上的人同意(这个比例在流程绘制时可以控制)才能进入下一个节点;
或签/非会签:一个节点有多个审批人,任一审批人同意即可进入下一节点;
加签:在节点中添加审批人;
减签:在节点中去除审批人;
抄送和退回、驳回比较简单,不再解释。
在现流行的 ruoyi flowable 的免费衍生框架中,大部分都是使用的在线表单,一般分为两种:
- 路由表单:自己编写的前端页面,vue 或者 html 使用 json 存储在数据库中,使用时需要按照示例的模板,比较繁琐,和正常写前端页面相比不完美的地方很多;
- 在线表单:使用一些绘制工具(vForm 等),在平台使用拖拉拽方式编辑布局,使用表达式或者变量自行设计的表单;
无一例外,他们都在数据库中存储了表单的结构,不说读取速度如何,单纯就复杂业务来讲,难以满足,只有非常简单的情况下才去使用(简单的审批自己实现就好,也不需要引入流程框架)。
业务实现中一般使用外置表单,该表单对应数据库中的一张表,和平常业务相同,然后每条记录中增加两个与工作流相关的字段:流程实例id、审批状态,这样我们就可以据此回溯流程的结果,并且借助 flowable 的监听器去同步状态。
Flowable7
本文只描述 Flowable 7.x 与 Spring Boot3 的集成,其实和以前的方式几乎一样。Flowable 7.x 是目前最新的版本,专注于 Spring Boot 3、Spring 6 和 Java 17 的升级。
Flowable 7 开始,删除了内置的 web ui 流程设计器,官网上推荐注册一个 flowable 云平台的账号免费在上面进行流程绘制,然后下载导入程序。
引入依赖
1 | <dependency> |
配置文件:
1 | spring: |
如果是多数据源,且对数据源的重写程度较大,那么 flowable 可能不会读取配置,程序启动时还是使用内置的 h2 数据库,如果有无法建表的错误,大概率是此原因。
配置文件:
1 | # flowable 配置 |
读取 flowable 的配置:
1 |
|
设置数据源:
1 |
|
但是上面的解决办法会引入新的问题:数据源切换事务可能会出问题,不过由于目前没有用到多数据源(采用的框架支持),所以没有深入。
表结构说明
flowable 启动时如果数据库没有相关的表结构会自动创建,一共有 70 张表,根据表前缀分类大致如下:
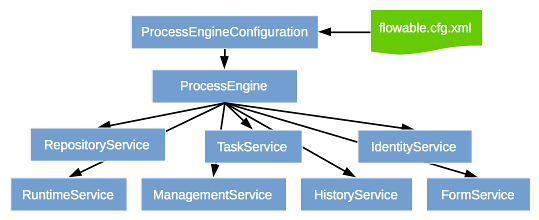
ACT_RE_:RE 代表 repository(存储)。这些表包含静态信息,如流程定义和流程的资源(图片、规则等)。由 RepositoryService 接口操作。
ACT_RU_:RU 代表 runtime。这些表存储运行时信息,如流程实例、用户任务、变量、作业等。Flowable 只在流程实例运行中保存运行时数据,并在流程实例结束时删除记录,以保证运行时表小且快。由 RuntimeService 接口操作。
ACT_HI_:HI 代表 history。这些表存储历史数据,如已完成的流程实例、变量、任务等。由 HistoryService 接口操作。
ACT_ID_:ID 表示 identity(组织机构)。这些表包含标识的信息,如用户、用户组等。由 IdentityService 接口操作。
ACT_GE_:通用数据表,用于存储各种情况下都可能需要的数据。
还有其它的表,但是使用的频率应该不高?浪子基本用不上。
核心表:
ACT_GE_BYTEARRAY:xml 文件元数据;
ACT_RE_DEPLOYMENT:绘制的 xml 文件信息保存在这里面,并且带着自定义的名称和分类等基础信息;
ACT_RE_PROCDEF:流程定义表,一次部署可以部署多个流程,一个流程对应一条记录,key 默认是 xml 的 id;
ACT_RU_ACTINST:流程实例表,对应申请用户发起的审批申请;
ACT_RU_TASK:用户任务表,工作流执行的最小单位,该表存储每个流程实例当前运行到的那个节点信息,每个任务完成后自动删除(常用于查询人员或部门的待办任务);
ACT_RU_EXECUTION:执行分支表,记录运行中流程运行的各个分支节点信息,流程结束后删除;
ACT_HI_PROCINST:历史流程实例表,存储流程实例历史数据(包含正在运行的流程实例)。每启动一个流程实例,ACT_HI_PROCINST 中就会维护一条记录;
ACT_RU_TASK 表只会存在当前流程中当前执行到的节点,之所以说他是最小的执行单位是因为我们在绘制流程图的时候大部分会在此为每个 userTask 设置信息:审批人、监听器、变量等等。
flowable starter 的操作 bean
使用 Flowable 的 starter,这些 bean 可以通过 IOC 注入直接使用,也可以使用 ProcessEngine#getXXX 的方式获取:
1 | // 第一种,通过 processEngine 获取 |
接入自己系统的组织架构和人员
有时会有这样一种情况,已经存在的系统需要接入 flowable,那么我们基本不会使用内置的组和成员,而是需要接入自己系统的组织和人员。实现方式多种多样,一般会在流程绘制阶段在 userTask 中直接设置,因为审批人多数情况下不会变动。此时通过后端返回已有的用户以及组织列表(就像系统管理的用户管理),前端做一个弹窗进行展示以及选择,然后传给后端,无论是用户的 id 还是用户名,只要能据此查找到用户就行,后面就交给后端实现。
在绘制的 xml 流程图阶段,userTask 标签中有一个 assignee 的属性,把能代表用户的标志传给后端,并且 flowable 会存储在自己的表中。主要是在前端页面设计接入,传递给后端即可。candidateUsers 是候选用户,candidateGroups 候选组,满足多种不同的需求。
1 | <!-- 截取部分说明,flowable:assignee 的值为 3,这是数据库用户的 id --> |
ExecutionListener 执行监听器
自定义 ExecutionListener 的实现类,在表单设计的时候在最后一个结点添加该监听器,这样通过时就可以拿到了。
监听器同样可以在定义 userTask 的时候进行动态的选择。监听器只会对配置了的 userTask 生效。